A short article to inform you that I’ve just published a proof of concept of JWT token validation with NGINX using NJS. NJS is a subset of Javascript that allows extending NGINX functionalities: https://nginx.org/en/docs/njs/
Please note: NGINX can already validate JWT Tokens, but only if you pay for the Plus subscription. Thanks to NJS we can now validate JWT Tokens with the free version of NGINX.
In this article we’ll take a look at the performance cost (or “overhead”) of using AWS Lambda@Edge ( https://aws.amazon.com/lambda/edge/ ) on a CloudFront distribution.
Note: In this article I won’t explain how to create these resources (you can find detailed instructions on the official AWS pages), but I want to focus on the test cases.
You can use Lambda@Edge to execute arbitrary Lambda Functions on your requests, for example to authenticate an user through a JSON Web Token ( https://jwt.io ) before routing them to a static asset.
The main advantage of Lambda@Edge is that the code (Javascript) is executed “near to the edge”, so really clouse to the edge location, and so with a small performance cost.
So, for testing this:
I created an S3 bucket with two files: a sample image (124KB) and an empty txt file
I created two CloudFront distributions pointing to the same bucket, one distribution triggering a Lambda@Edge function that takes the querystring and adds it in a custom header, and the other simply serving the content without further check
The first request pass through the Lambda@Edge function, so its response headers will be like these:
Content-Type: image/jpeg … test-header: EXAMPLEQUERYSTRING … X-Cache: Hit from cloudfront
As you can see, there is a `test-header` with the content of the querystring. This is unuseful in a real world situation, but we use it to understand how much is the overhead of a REALLY simple Lambda function
Since the second request doesn’t pass through the Lambda function, its header doesn’t show the custom header
Content-Type: image/jpeg … X-Cache: Hit from cloudfront
Finally, we are ready to test it. For the tests, I choose to use an AWS EC2 instance to minimize the networking overhead (hopefully there is a good networking between EC2 and Cloudfront) 🙂
I used this simple script to collect the response times. It makes 1000 requests and adds the response time to a file:
TIMEFORMAT=%R
for i in {1..1000} do (time $(curl -s http://abc.cloudfront.net/cat.jpg?EXAMPLEQUERYSTRING > /dev/null)) >> 1.txt 2>&1 done
for i in {1..1000} do (time $(curl -s http://xyz.cloudfront.net/cat.jpg?EXAMPLEQUERYSTRING > /dev/null)) >> 2.txt 2>&1 done
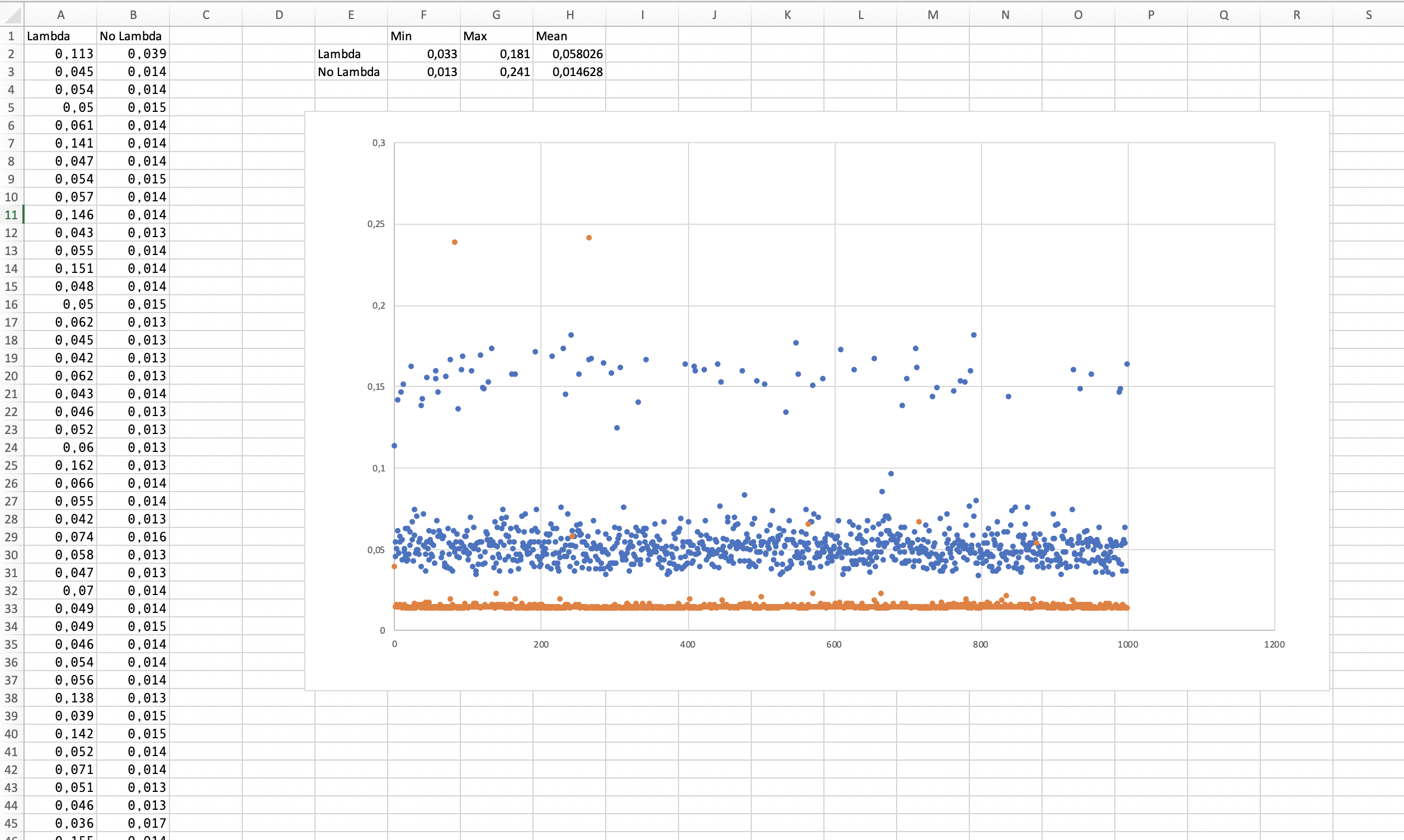
Here you can see the results:
In Orange, you see the distribution of the calls without the Lambda function, and in Blue the distribution of the calls WITH the Lambda function.
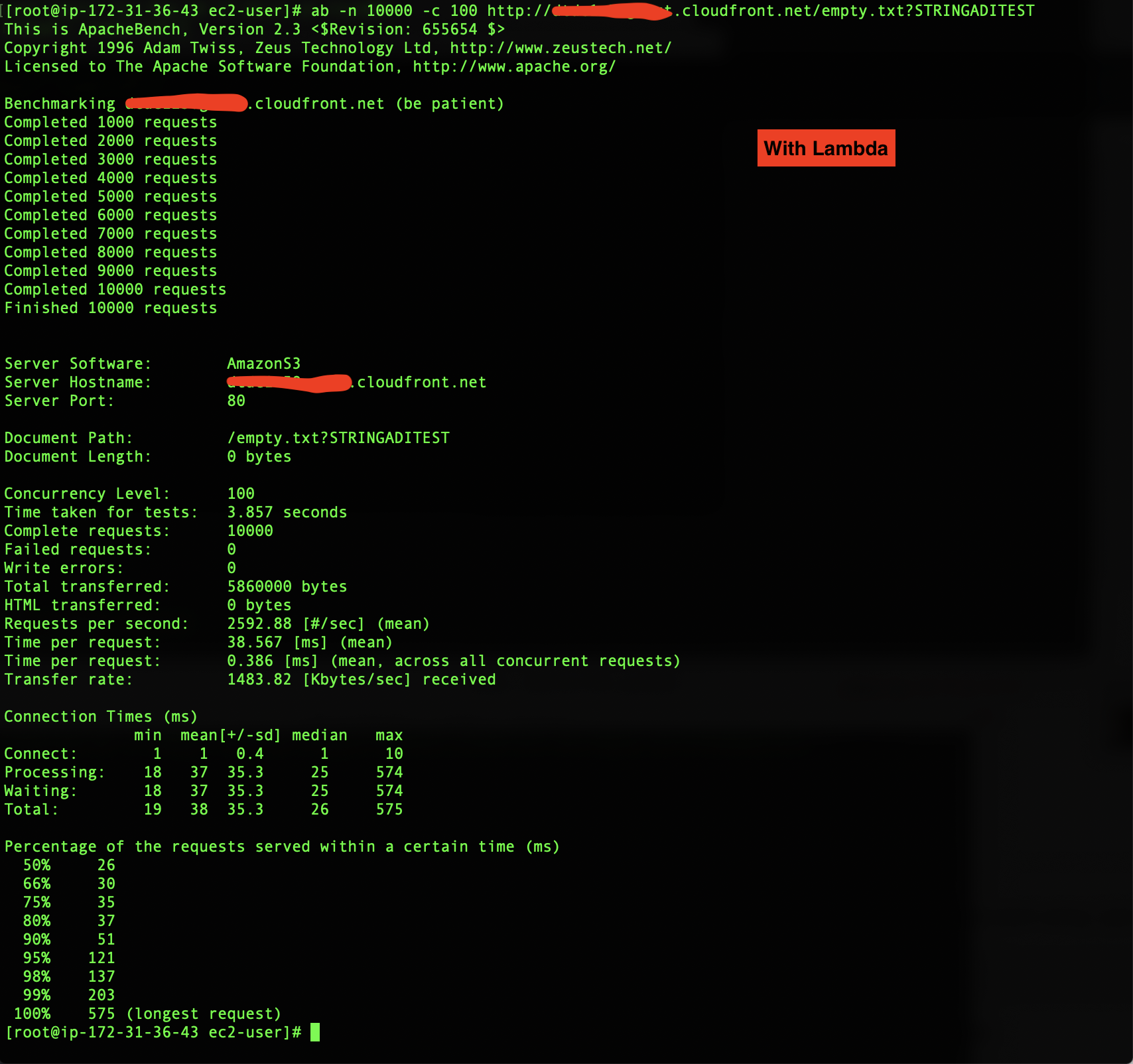
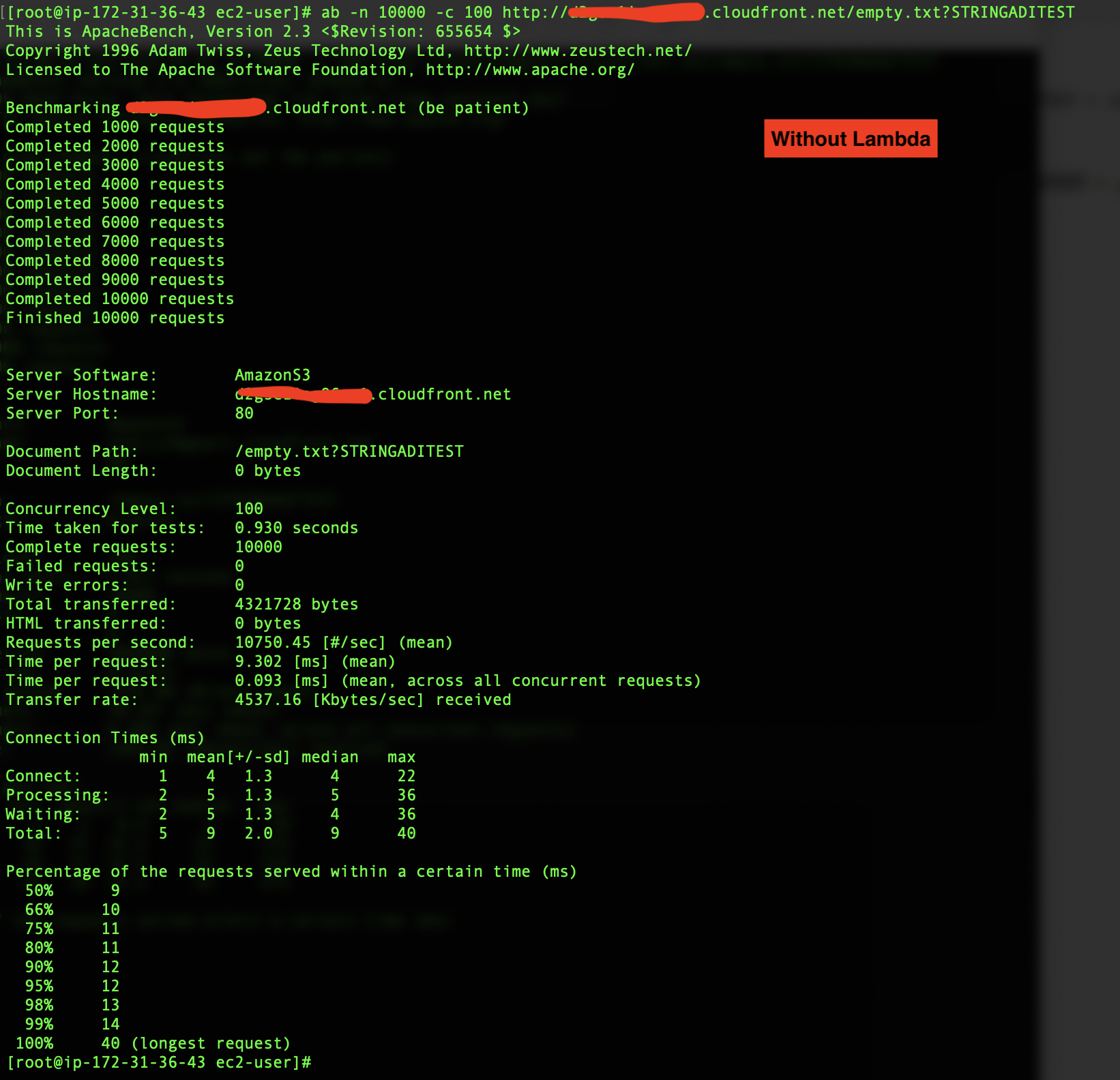
Finally, I decided to do some tests with ab (Apache Bench), in this cased I used 10.000 connections with 100 concurrent
As you can see in the Excel, there is a performance cost, since the mean moves from 0,015sec to 0,058sec. In the ab tests (with the empty.txt file), the mean moves from 9.3msec to 38.5msec. So rawly 4X.
But these timing are, in absolute, still pretty fast if we consider that they can be executed really close to the final user, and so no need to round trip to your compute-servers.
The next time I will try CloudFlare Workers, that claims to be 2X faster than AWS Lambda@Edge